1. Redis(Remote Dictionary Server)란?

Redis is an open source (BSD licensed), in-memory data structure store used as a database, cache, message broker, and streaming engine. Redis provides data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes, and streams. You can run atomic operations on these types, like appending to a string.
Introduction to Redis에서 발췌한 내용에 따르면, Redis는 in-memory 데이터 구조 저장소이며, strings, hashes, lists, sets, sortes sets과 같은 여러가지 데이터 구조를 제공하며 싱글 스레드로 Atomic을 보장해준다는 것을 알 수 있다.
우선, 위의 내용들을 통해 알 수 있는 점은 in-memory 구조로 DB에 직접적으로 접근하여 저장하는 것이 아니라 메모리에 접근하여 데이터를 가져옴으로 속도면에서 향상된다는 점과 여러가지 데이터 구조를 제공해줌으로 원하는 데이터를 저장/조회할 때 데이터 구조를 직접 만들어 접근하는게 아니라 제공하는 데이터 구조를 이해하여 편하게 접근한다는 것이다. 또한, Redis는 싱글 스레드로 한꺼번에 많은 요청이 일어나도 순차적으로 업무를 처리하므로 Race Condition도 피할 수 있다.
간단하게 Redis에 대해 알아보았는데, 이제는 좀 더 상세하게 알아보도록 하자.
2. Cache란?
Redis는 앞에서 말했던 것처럼, in-memory 구조로 Cache 메모리에 데이터를 보관해두었다가 필요로 할 때 Cache 메모리에 접근하여 데이터를 돌려준다.
Cache의 읽기/쓰기 패턴은 아래와 같다.
2.1 Look Aside
Cache 읽기 요청 패턴 중 주로 쓰이는 방법으로 요청 데이터가 Cache 서버에 있는지 조회한 후, 없다면 DB 서버를 조회하여 가져온 데이터를 다시 Cache 서버에 담아준다.
2.2 Read Through
Read Through 패턴은 무조건 Cache 서버를 통해서만 데이터를 읽어오는 방식이다. 모든 정보를 Cache 서버에서 조회해옴으로 데이터 정합성에 대한 문제가 발생하지는 않지만, Cache 서버에 문제가 생길 경우, 해당 데이터들이 휘발되어 문제가 발생할 수 있다.
2.3 Write Back
Cache 서버에 먼저 저장해두고 해당 데이터를 반환해주면 특정 시점마다 Cache 서버에 있는 데이터를 DB서버에 저장해주는 방식이다. Write Back은 쓰기 작업이 많이 발생하는 경우 일일이 INSERT 쿼리를 날리지 않고 모았다가 한 꺼번에 날리는 방식이다.
일일이 INSERT 쿼리를 날리는 것보다 한 꺼번에 INSERT문을 처리하는 것이 속도적인 면에서도 매우 빠르다. 하지만, DB에 저장하기 전에 Cache 서버에 문제가 생길 경우, 저장하기 전의 Cache 서버의 데이터가 날아갈 수도 있다는 단점이 있다.
2.4 Write Through
Write Through 패턴은 Cache 서버에 반영하고 바로 DB 서버에도 반영하는 방식이다.
2.5 Write Around
Write Around는 모든 데이터를 DB서버에 반영한다.
2.6 Redis vs Memcached
In-memory DB로 가장 많이 사용되는 2가지로 Redis, Memcached를 예로 들 수 있을 것이다. 그렇다면 Memcached를 이용한 방식도 있는데 왜 Redis를 써야할까?
여러 비교 대상을 들 수도 있겠지만 아마 가장 큰 이유는 Redis가 지원하는 여러가지 데이터 구조가 아닐까?
Memcached의 경우, Strings, Integers의 구조만 지원한다. 만약, Collection 구조가 필요할 경우 해당 구조를 우리가 직접 구현해야 한다. 하지만 이와 달리 Redis는 위에서 말했듯이 여러가지 구조를 기본적으로 제공해준다. 단순히 우리는 Cache 서버를 사용하기 위해서 Memcached를 사용했는데, Collection 구조까지 직접 구현해야 한다면 배보다 배꼽이 더 커지는게 아닐까?
Redis에서 제공하는 여러가지 구조를 통해서 우리는 구현하고자 하는 기능들의 개발 편의성과 구현 난이도까지 쉽게 가져갈 수 있다.
예를 들어 랭킹 서버를 직접 구현해야 한다면? -> Redis의 Sorted Set을 이용하면, 랭킹을 쉽게 구현할 수 있다.
이 외의 Redis와 Memcached 성능 비교 및 차이점을 알고 싶다면 아래의 링크를 확인해보도록 하자.
[REDIS] 📚 레디스 소개 & 사용처 (캐시 / 세션) - 한눈에 쏙 정리
Redis (Remote Dictionary Server) Redis는 Remote(원격)에 위치하고 프로세스로 존재하는 In-Memory 기반의 Dictionary(key-value) 구조 데이터 관리 Server 시스템이다. 여기서 key-value 구조 데이터란, mysql 같은 관계형
inpa.tistory.com
3. 개인 프로젝트에 Redis 사용해보기
Redis는 in-memory 구조로 Cache 서버에서 데이터를 조회해오기 때문에 실제 DB 서버를 통해 데이터를 조회해오는 과정보다 속도가 빠르다.
하지만, 이는 실제 사용자의 수가 증가할 수록 더 많은 이득을 볼 수 있는 부분으로 현재 내가 개발 중인 서비스에서는 테스트 사용자만 존재하기 때문에 얼마 만큼의 이득을 볼 지는 장담할 수 없다.
하지만, 서비스의 사용자는 언제 어디서든 증가할 수 있기 때문에 서버의 부하가 생길 수 있다고 생각하는 기능에 대해 Redis로 전환하여 처음부터 서비스를 제공하는 방법이 좋을 거 같다. 서비스 제공 중에 부하가 생겨 즉각 조치가 필요할 경우, 갑자기 Redis로 전환할 수 도 없고 이 때는 서버 Scale Up/Out 방법밖에 없을거기 때문에 미리 선 조치 한다는 생각으로 Redis로 전환하였다.
3.1 어떤 기능을 Redis로 전환할 것인가?
선곡 리스트의 곡들을 좋아요 할 수 있는 기능이 있는데 이를 Redis로 전환해 볼 것이다. 왜 굳이 이 기능을 Redis로 전환하냐면,
- 좋아요 설정/해제는 자주 발생하는 이벤트로 사용자가 증가할 수록 해당 이벤트의 사용 빈도도 증가할 것이다. 그렇다면 매번 DB 서버에 직접 INSERT/DELETE 시, 서버의 부하가 증가할 수 있다.
- Redis에서 제공하는 Set, 정렬이 필요하다면 Sorted Set을 이용하여 좀 더 간편하게 데이터를 조회해올 수 있다.
3.2 Redis 서버 세팅
Redis 설치 서버를 따로 만들지 테스트용이기 때문에 애플리케이션 서버에 설치할지 고민하다가 Redislabs에서 1개의 레디스 DB를 무료 공간을 제공해준다는 것을 알고 Redislabs를 통해 Redis 서버를 만들었다. 30MB 제약이 있지만, 테스트 서버로 사용하기에는 무리가 없어 보인다.
[Redislabs] 📚 Redis를 클라우드로 사용하자
Redis 클라우드 MySQL을 사용하기 위해서 워크벤치를 설치했던 것 처럼, 레디스를 사용하려면 레디스 데이터베이스를 설치해야 한다. 직접 서버 컴퓨터에 직접 설치할 수도 있지만, 레디스를 호스
inpa.tistory.com
3.3 Redis 명령어
Redis에서 사용되는 명령어는 무수히 많지만, 그 중 가장 많이 쓰이는 몇 가지만 정리해보았다. 이 외의 다른 명령어들은 Redis 명령어 모음에서 확인해보자.
Commands
redis.io
또한 Redis는 해당 명령어를 사용해 볼 수 있는 테스트 사이트를 제공해준다.
| 명령어(Strings) | 명령어 설명 | Example |
| keys | 저장되어 있는 키값들을 확인 | keys * |
| set | 데이터 저장 | set [key] [value] |
| get | key 값을 이용하여 데이터 조회 | get [key] |
| mset | 여러 데이터를 한꺼번에 저장 | mset [key1] [value1] [key2] [value2] … |
| mget | 여러 key 값의 데이터 조회 | mget [key1] [key2] [key3] … |
| exists | 해당 key 값이 존재하는지를 integer로 return (있다면 1, 없다면 0) | exists [key] |
| keys ** | 해당 단어가 포함된 key 조회 | kyes keyword |
| rename | 기존 key 값을 변경 | rename [기존 key] [변경할 key] |
| del | 해당 key 값 데이터를 삭제 | del [key] |
| getdel | key 값을 이용해 조회 후 삭제 | getdel [key] |
| append | 해당 key value에 문자열을 더함 | append [key] [추가할 value] |
| type | key의 타입을 조회 | type [key] |
| flushall | 전체 데이터 삭제 | flushall |
| 명령어(Lists) | 명령어 설명 | Example |
| lpop | 맨 앞 원소를 제거한 후, count 수 만큼의 elements를 반환 | lpop [key] [count] |
| lpush | 맨 앞에 데이터를 추가 | lpush [key] [element] |
| rpop | 마지막 원소를 제거한 후, count 수 만큼의 elements를 반환 | rpop [key] [count] |
| rpush | 마지막에 데이터를 추가 | rpush [key] [element] |
| lrange | 지정된 범위만큼 elements를 반환 | lrange [key] [startIndex] [endIndex] |
Sets에서는 집합이라는 의미에서 value를 member라 부릅니다.
| 명령어(Sets) | 명령어 설명 | Example |
| sadd | member를 추가 | sadd [key] [member] |
| scard | member의 갯수를 반환 | scard [key] |
| srem | member를 삭제 | srem [key] [member] |
| smembers | 모든 member를 반환 | smembers[key] |
3.4 코드에 적용하기
public long like(Like like) {
SetOperations<String, Like> setOperations = likeRedisTemplate.opsForSet();
boolean hasLike = getLike(like);
if (!hasLike) {
return setOperations.add("like", like);
} else {
setOperations.add("unlike", like);
return setOperations.remove("like", like);
}
}전체 코드는 생략하고, 실제 적용된 부분의 코드만 간략하게 소개하도록 하겠다.
좋아요 이벤트가 발생하면, 아래와 같이 실행된다.
- Redis 서버에 해당 data가 있는지 조회
- 없다면, “like”라는 키로 data를 저장
- 있다면, “unlike”라는 키로 data를 저장하고, 이 때의 data는 좋아요 해제 data로 “like”에서는 삭제
- 일정 시간이 지나면, Redis 서버의 “like” 키를 가진 data는 INSERT, “unlike” 키를 가진 data는 DELETE
실제 DB에 반영하는 주기라던지, Redis 서버에 담을 data 등은 실제 서비스를 어떻게 구현하고 해당 기능을 사용할건지에 대해서 달라질 수 있다.
해당 서비스에서는 @Scheduled을 이용하여, 5초마다 DB에 반영해주도록 설정하였다. 화면에서는 좋아요를 누를때마다 Icon만 변경해주고, 실제 반영은 5초마다 일어난다. 여기서 5초로 설정한 이유는, 좋아요 페이지를 벗어나 다른 페이지로 전환했다가 다시 해당 페이지로 돌아오는 시간을 대략적으로 5초로 지정하여 설정하였다.
이 부분에 대해서는 실제로 여러 사용자들이 서비스를 사용하면서 해당 페이지에 머무는 시간, 해당 페이지를 벗어났다가 돌아오는 경우 등의 사용자 패턴 데이터들을 이용하여 적절하게 변경해주면 좋을 거 같다.
4. DB Server VS Redis Server
좋아요 기능에 대해 DB Server에 실시간으로 반영하는 방법과 Redis를 이용한 Cache 서버를 이용하는 방법에 대해 비교해보자.
공통적으로 모두 User의 수는 100명, 1000명, 3000명 단위로 테스트 해 보았다.
또한, 첫 번째 테스트는 좋아요만 하는 경우로 테스트를 해보았고, 두번째는 좋아요와 좋아요 해제를 연달아 하는 경우에 대하여 테스트 해보았다.
4.1 DB Server
4.1.1 좋아요만
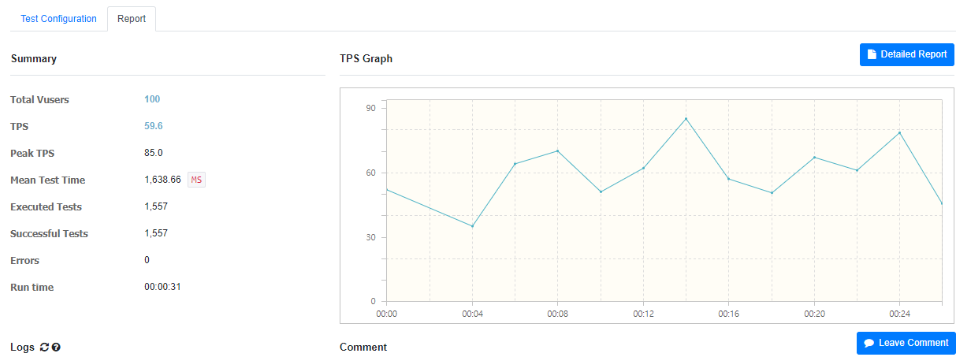
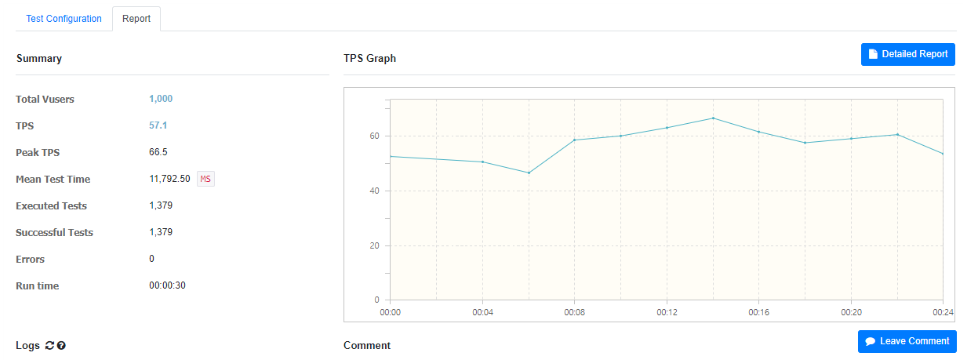
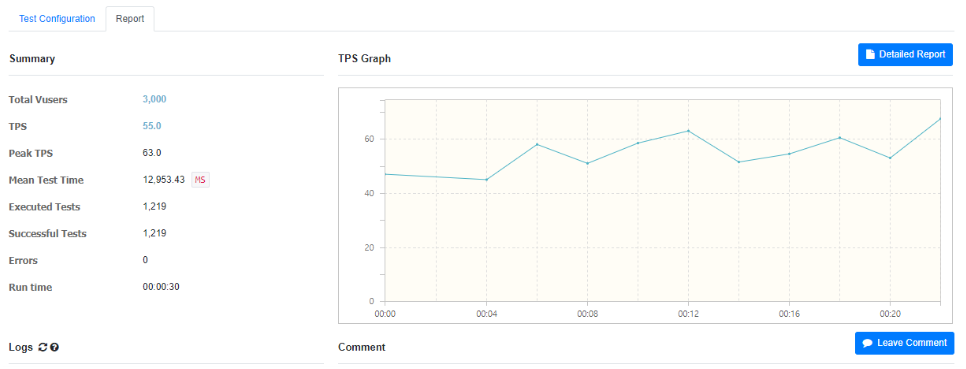
순서대로 사용자의 수는 100명, 1,000명, 3,000명의 테스트 결과이다.
TPS 수치만 확인해보았을 때, 59.6/57.1/55.0 비슷한 수치 결과를 확인할 수 있다.
4.1.2 좋아요 & 좋아요 해제
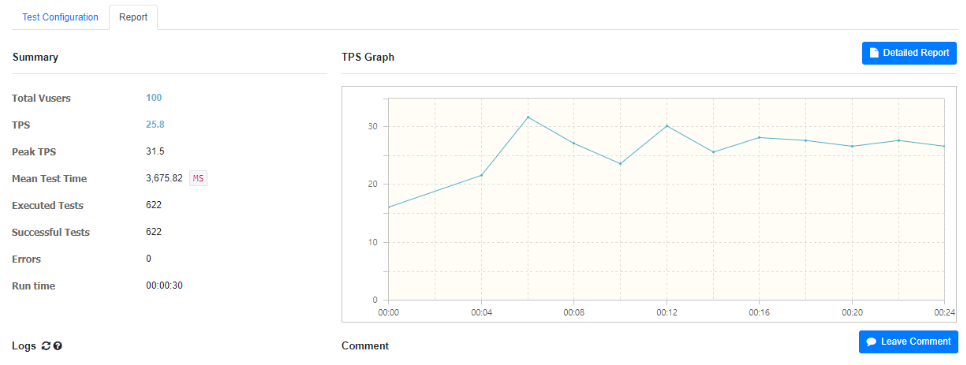
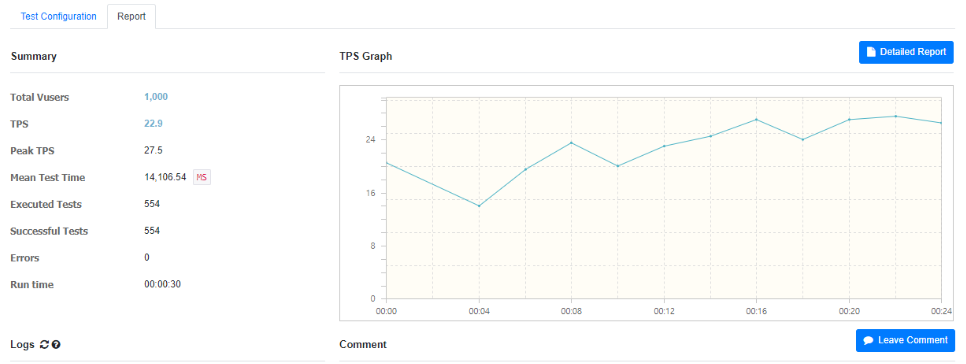

좋아요 설정 & 해제가 연달아 일어날 경우, TPS 수치는 25.8/22.9/23.0으로 좋아요만 실행하는 경우의 절반 이하로 떨어지는 것을 확인할 수 있다.
그렇다면, Cache 서버를 통해 좋아요 기능을 구현하면 그 결과는 어떻게 나올까?
4.2 Cache Server
4.2.1 좋아요만
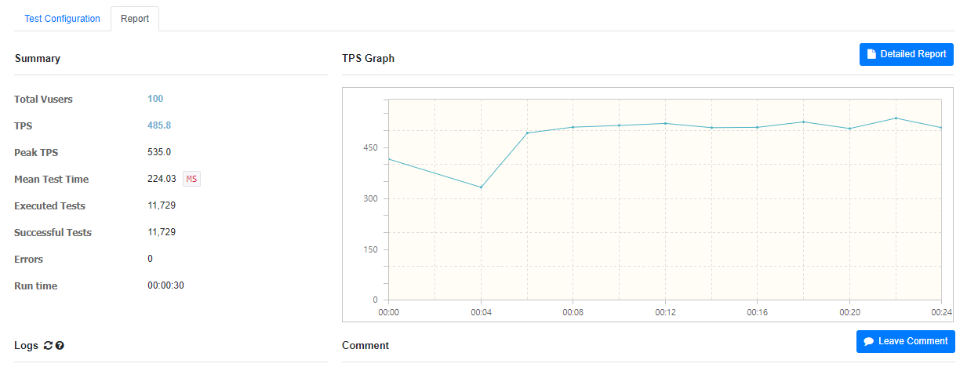

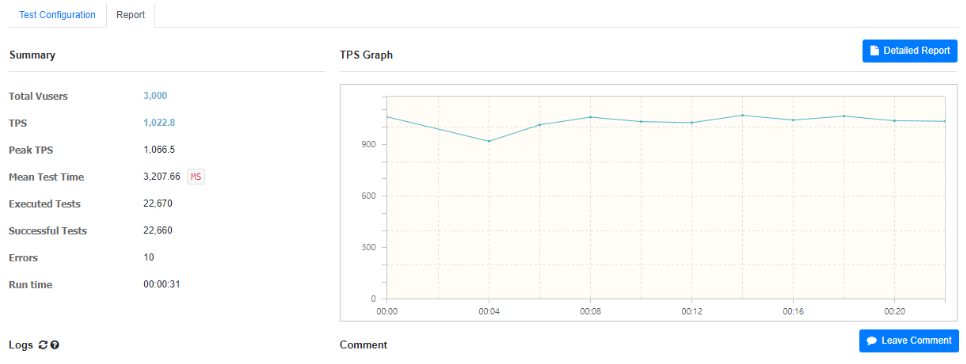
Redis를 이용하여 좋아요 테스트를 했을 경우, 사용자의 수에 따라 TPS는 485.8/991.1/1,022.8의 결과가 나온 것을 확인할 수 있다. 단순히 비교해도 최소 10배 이상 수행할 수 있는 것을 확인할 수 있다.
4.2.2 좋아요 & 좋아요 해제


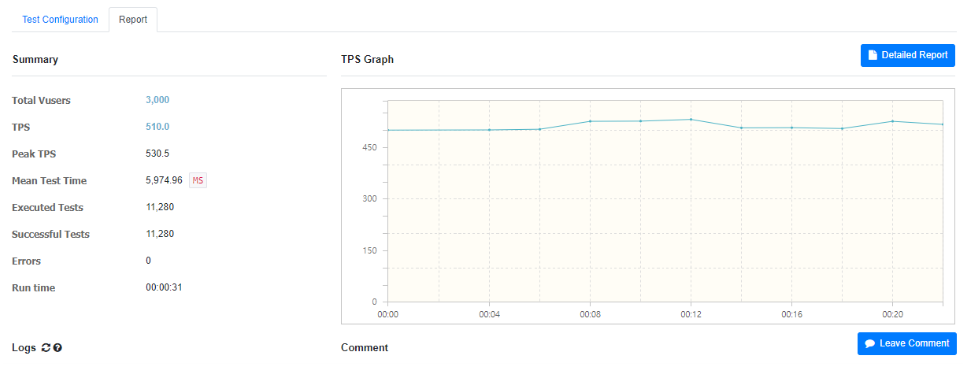
좋아요 설정 & 해제의 경우에도, TPS 수치는 247.7/491.4/510.0의 결과가 나온 것을 확인할 수 있다.
비교하기 좀 더 편하게 아래의 표를 통해 다시 확인해보자.
4.3 비교
테스트 결과값 중에 TPS, Mean Test Time(MTT) 결과를 비교해보자.
4.3.1 좋아요만
| Users/TPS | DB | Redis | |
| 100명 | 59.6 | 485.8 | -> 8.15배 향상 |
| 1,000명 | 57.1 | 991.1 | -> 17.35배 향상 |
| 3,000명 | 55.0 | 1022.8 | -> 18.6배 향상 |
| Users/MTT(ms) | DB | Redis | |
| 100명 | 1,638.66 | 224.03 | -> 7.31배 향상 |
| 1,000명 | 11,792.50 | 1,403.86 | -> 8.4배 향상 |
| 3,000명 | 12,953.43 | 3,207.66 | -> 4.04배 향상 |
4.3.2 좋아요 & 좋아요 해제
| Users/TPS | DB | Redis | |
| 100명 | 25.8 | 247.7 | -> 9.6배 향상 |
| 1,000명 | 22.9 | 491.4 | -> 21.46배 향상 |
| 3,000명 | 23.0 | 510.0 | -> 22.17배 향상 |
| Users/MTT(ms) | DB | Redis | |
| 100명 | 3,675.82 | 489.07 | -> 7.52배 향상 |
| 1,000명 | 14,106.54 | 2,762.82 | -> 5.11배 향상 |
| 3,000명 | 13,506.66 | 5,974.96 | -> 2.26배 향상 |
좋아요/좋아요 해제 기능의 부하 테스트 결과를 확인해봤을 때, Redis 서버를 이용한 결과가 모든 결과에서 긍정적으로 나왔다.
초당 처리할 수 있는 지표인 TPS는 최소 8.15배에서 최대 22.17배로 높게 나왔고, 응답 시간 또한 최소 2.26배에서 최대 8.4배 빨리 나왔다.
좋아요 기능과 같이 이벤트가 자주 일어나는 기능이라면, 매번 DB 서버에서 INSERT/DELETE가 일어나는 것보다 캐시를 활용한 Redis 서버를 이용하면 위와 같이 성능면에서도 향상된 결과를 확인할 수 있다.
5. 마무리
좋아요 기능 구현에 대해 검색을 하면 모두 Redis 활용하여 구현한 것을 예제로 많이 보았다. 그런데 왜 굳이? Redis를 이용하여 만들어야 할까?에 대해서는 크게 생각해보지 않았던 거 같다.
그래서 왜 Redis 서버를 이용하여 좋아요 기능을 구현하면 좋을까에 대해서 직접 테스트 해보았다. DB 서버에 실시간으로 INSERT/DELETE 하는 경우와 Redis를 이용하여 구현한 방법까지 구현하여 테스트해보았다.
테스트 결과를 예상했을 때, 당연히 Redis의 서버가 높을 거라는 예상은 있었지만, 최대 20배 이상의 효율을 내는 것을 생각하지 못했다. Redis의 어떤 설정값을 바꾼다면 그 이상의 효율도 나오지 않을까 생각하였다.
테스트를 통한 결과로 사용자가 많은 서비스일수록, 또는 자주 사용되는 기능일수록 적절하게 Cache를 이용하여 서비스의 부하가 일어나는 부분을 해결할 수 있지 않을까 생각하였다.
참고 사이트:
[REDIS] 📚 레디스 소개 & 사용처 (캐시 / 세션) - 한눈에 쏙 정리
Redis (Remote Dictionary Server) Redis는 Remote(원격)에 위치하고 프로세스로 존재하는 In-Memory 기반의 Dictionary(key-value) 구조 데이터 관리 Server 시스템이다. 여기서 key-value 구조 데이터란, mysql 같은 관계형
inpa.tistory.com
Docs
redis.io